
Description: this article is talking about some feedbacks from the book of “JianZhi Offer”
数组
- 一个连续的内存并且按照顺序存储数据
- 创建数组时候,我们需要首先指定数组的容量大小,然后按照大小分配内存。(数组的空间效率不是很好,经常会有空闲的区域没有得到充分的利用)
- 根据下标在O(1)时间读写任何元素ArrayList
他的内部是通过数组实现的,它允许对元素进行快速随机访问。当数组的大小不能满足所需的存储时,就要将已经有的数组的数据复制到新的存储空间中。所以在它的中间位置插入或者删除元素时,需要对祖进行复制、移动、代价比较高。
因此它适合随机查找和遍历,不适合插入和删除。String
Stirng 是一个final 类,String类是通过char数组来保存字符串的。
JVM 内存机制:在class文件中有一部分来存储编译期间生成的字面常量以及符号引用,这部分叫做class文件常量池,在运行期间对应着方法区的运行时常量池。String str1 = "hello world";和String str3 = "hello world"; 都在编译期间生成了 字面常量和符号引用,运行期间字面常量"hello world"被存储在运行时常量池(当然只保存了一份)。通过这种方式来将String对象跟引用绑定的话,JVM执行引擎会先在运行时常量池查找是否存在相同的字面常量,如果存在,则直接将引用指向已经存在的字面常量;否则在运行时常量池开辟一个空间来存储该字面常量,并将引用指向该字面常量。1 | String s1 = "hello"; |
new 关键字
通过new关键字来生成对象是在堆区进行的,而在堆区进行对象生成的过程是不会去检测该对象是否已经存在的。 因此通过new来创建对象,创建出的一定是不同的对象,即使字符串的内容是相同的。StringBuilder
通过Stirng作连续多次修改,每一次修改都会产生一个临时对象,这样开销太大会影响效率,使用StringBuilder只生成一个对象,并使用append在原有对象的基础上进行操作。1 |
|
StringBuffer
StringBuffer类的成员方法前面多了一个关键字(Synchronized),在多线程访问时候起到安全保护作用,StringBuffer是线程安全的1 |
|
链表
链表是一个动态数据结构,在创建链表时候,不需要知道链表的长度。当插入一个节点时候,我们只需要为新节点分配内存,然后调整指针的纸箱来确保新节点被链接到链表中。
内存分配不是在创建链表时候一次性完成的,而是每添加一个节点分配一次内存。由于没有闲置的内存,链表的空间效率比数组高。
由于链表中内存不是一次性分配的,因为我们无法保证链表的内存和数组一样是连续的。因此,如果想在链表中找到它的第i个节点,那么我们只能从头节点开始,沿着指向下一个节点的指针遍历链表,它的时间效率为O(n).
链表的循环遍历时候效率不高,但是插入和删除时优势明显。
单向链表
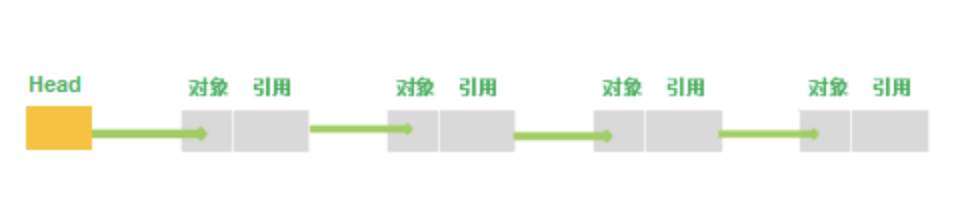
单向链表是一种线性表,实际上是由节点(Node)组成的,一个链表拥有不定数量的节点。其数据在内存中存储是不连续的,它存储的数据分散在内存中,每个结点只能也只有他能知道下一个结点的存储位置。向外暴露的只有一个头节点(Head),我们对链表的所有操作,都是直接后者间接地通过其头节点来进行的。
Java code to implement a linked list
1 | // define a Node |
树
除根节点之外每个节点都有一个父节点,根节点没有父节点,除叶节点之外所有节点都一个或多个子节点,叶节点没有子节点。父节点和子节点之间用指针链接。
二叉树
二叉树是树的一种特殊结构,在二叉树中每个节点最多只能有两个子节点。
- 先序遍历:根左右
- 中序遍历:左跟右
- 后序遍历:左右根
二叉搜索树
左子节点总是小于或等于根节点,而右子节点总是大于或等于根节点。
堆
- 最大堆:根节点的值最大
- 最小堆:根节点的值最小
红黑树
是树中的节点定义为红黑两种颜色,确保从根节点到叶节点的最长路径的长度不超过最短路径的两倍。

